任务需求:
下载 100 个 Github 上的 powershell 脚本作为数据库,用于之后的研究分析
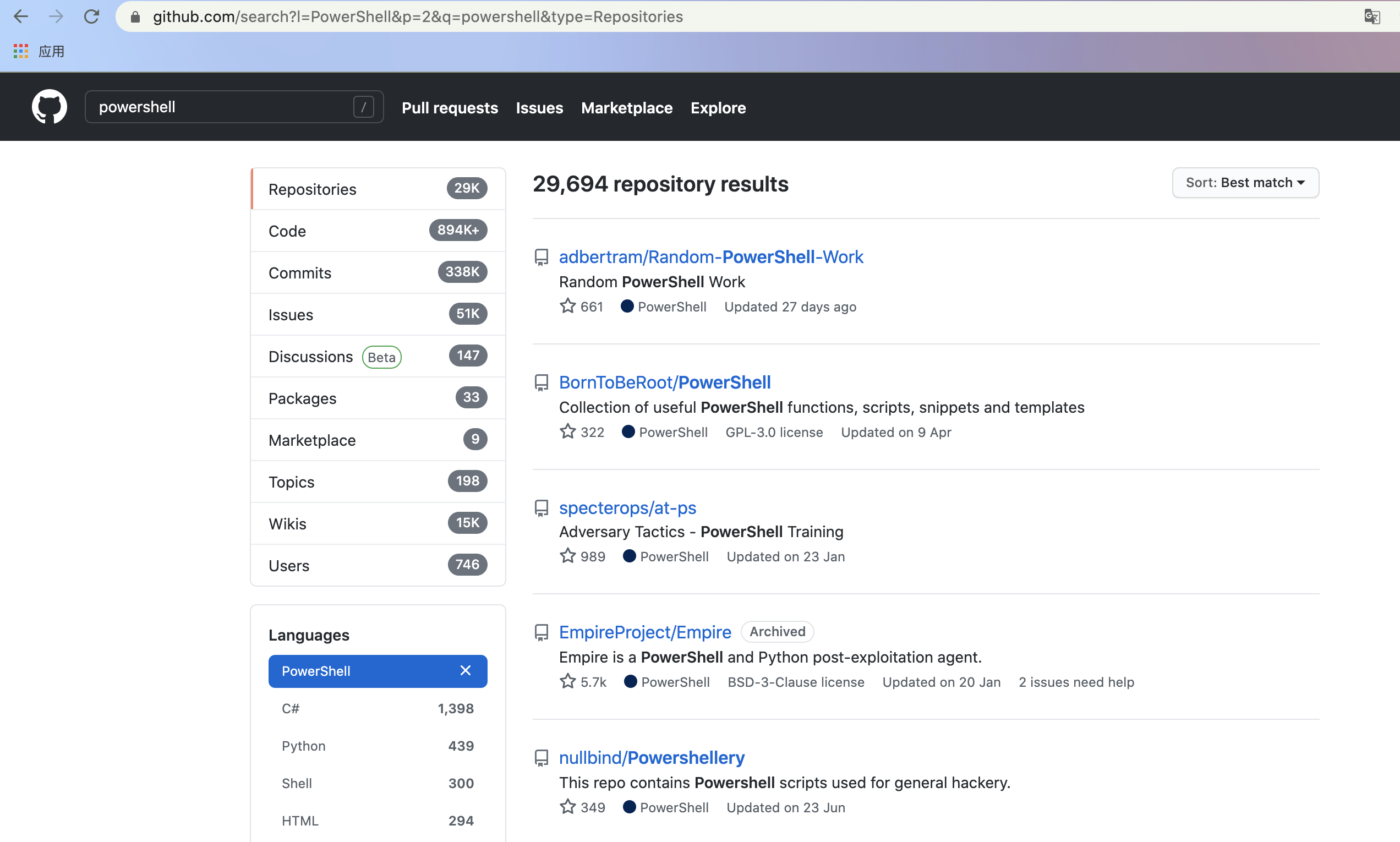
# 解析 Github 搜索页面,获取页面上的仓库名称# 分析 Github 搜索请求在 Github 上进行 powershell 搜索,选定语言为 PowerShell ,结果如下图
观察链接地址 https://github.com/search?l=PowerShell&p=2&q=powershell&type=Repositories 可知,有 4 个搜索参数: l 编程语言、 p 当前页数、 q 搜索内容、 type 搜索类型
# python 获取指定 url 的 html 并进行解析参考博客: https://blog.csdn.net/bull521/article/details/83448781
第三方库: requests 文档 https://requests.readthedocs.io/zh_CN/latest/
pyquery 文档 https://pyquery.readthedocs.io/en/latest/api.html
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import requests from pyquery import PyQuery as pq base_url = "https://github.com" ''' 从url中获取html文本,解析并返回列表 @param url 要解析的链接 @return list ['仓库名1', '仓库名2', ...] ''' def get_repos (url ): headers = { 'Host' : 'github.com' , 'User-Agent' : 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' , } r = requests.get(url=url, headers=headers) if r.status_code != 200 : print ('网页加载错误' ) return [] doc = pq(r.text) repos = [] items = doc('a' ).filter ('.v-align-middle' ).items() for item in items: repos.append(item.text()) return repos url = "https://github.com/search?l=PowerShell&q=powershell&type=Repositories&p=1" repo_list = get_repos(url) print (repo_list)
结果如下:
1 ['lazywinadmin/PowerShell' , 'clymb3r/PowerShell' , 'danielbohannon/Invoke-Obfuscation' , 'RamblingCookieMonster/PowerShell' , 'PowerShellMafia/PowerSploit' , 'MicrosoftDocs/PowerShell-Docs' , 'FuzzySecurity/PowerShell-Suite' , 'dahlbyk/posh-git' , 'janikvonrotz/awesome-powershell' , 'dracula/powershell' ]
# 代码解析:使用 requests 获取 Github 响应
1 2 3 import requestsr = requests.get("https://github.com/search?l=PowerShell&q=powershell&type=Repositories&p=1" ) print (r.text)
分析返回的 html 文本,其中关于仓库的信息如下所示
1 2 3 4 <div class ="f4 text-normal" > <a class ="v-align-middle" data-hydro-click ="{" event_type" :" search_result.click" ," payload" :{" page_number" :1," per_page" :10," query" :" powershell" ," result_position" :2," click_id" :9093330," result" :{" id" :9093330," global_relay_id" :" MDEwOlJlcG9zaXRvcnk5MDkzMzMw" ," model_name" :" Repository" ," url" :" https://github.com/clymb3r/PowerShell" }," originating_url" :" https://github.com/search?l=PowerShell& q=powershell& type=Repositories& p=1" ," user_id" :24938068}}" data-hydro-click-hmac ="309d4f59b977bc66a4a930b1805d5bbc5cd5d76519a9d1f421fb14f094e253c8" href ="/clymb3r/PowerShell" > clymb3r/<em > PowerShell</em > </a > </div >
所以只需获取类 v-align-middle 对应的文本值即可,此时就需要用到另一个第三方库 pyquery
1 2 3 4 5 6 7 8 9 10 11 12 import requestsfrom pyquery import PyQuery as pq r = requests.get("https://github.com/search?l=PowerShell&q=powershell&type=Repositories&p=1" ) doc = pq(r.text) items = doc('a' ).filter ('.v-align-middle' ).items() repos = [] for item in items: repos.append(item.text()) print (repos)
1 ['adbertram/Random-PowerShell-Work' , 'BornToBeRoot/PowerShell' , 'specterops/at-ps' , 'EmpireProject/Empire' , 'nullbind/Powershellery' , 'microsoftgraph/powershell-intune-samples' , 'SublimeText/PowerShell' , 'ZHacker13/ReverseTCPShell' , 'MicrosoftDocs/windows-powershell-docs' , 'MicksITBlogs/PowerShell' ]
成功拿到搜索页面的仓库名
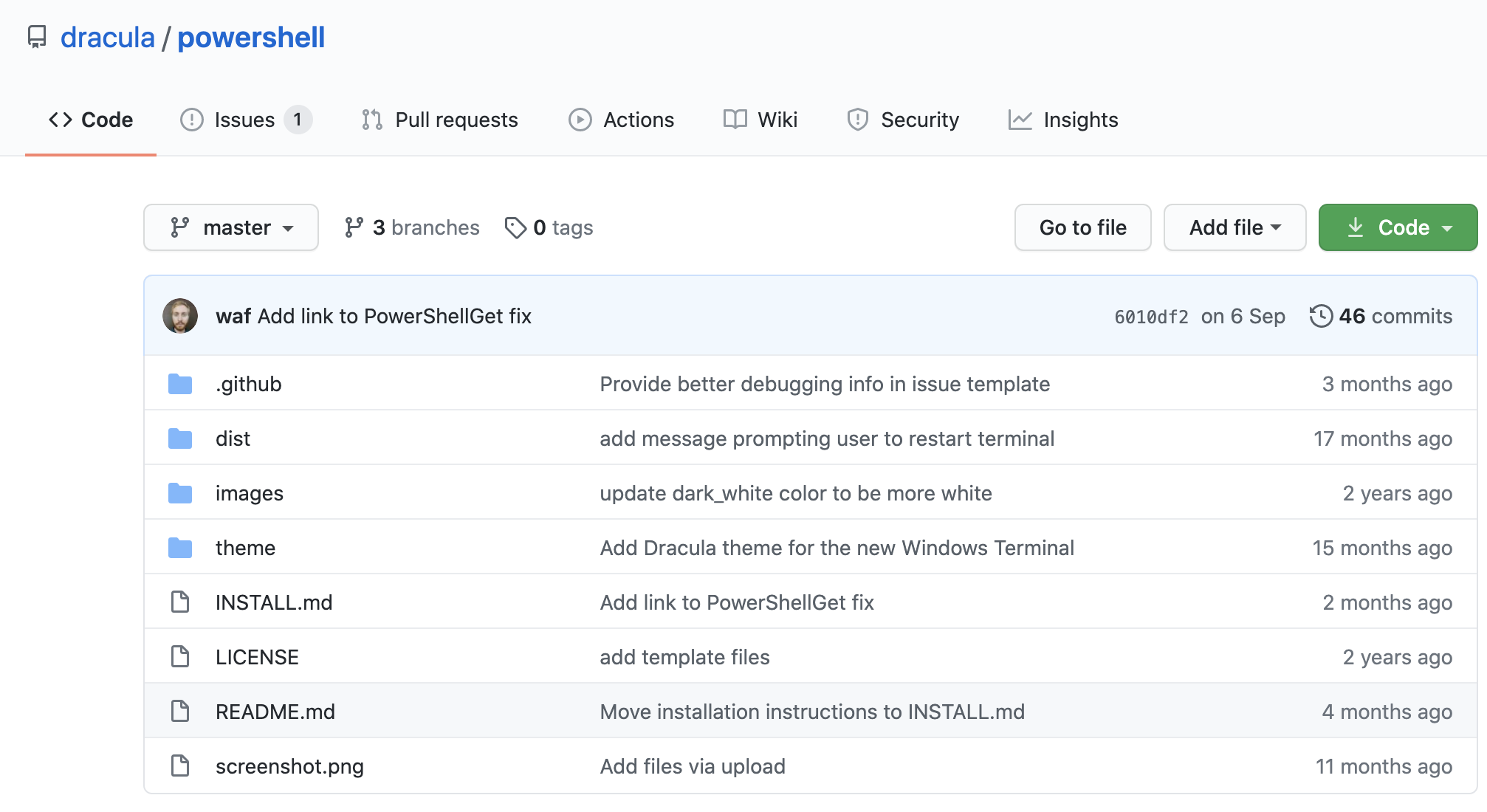
# 在 Github 仓库中遍历,找到所有的 powershell 文件# 分析单个仓库的 html 文本信息此时 url 设置为 “https://github.com/dracula/powershell ”,仓库目录如下所示
分析 html 文本,找到文件链接,如下所示
1 2 3 4 文件超链接 <a class ="js-navigation-open link-gray-dark" title ="INSTALL.md" href ="/dracula/powershell/blob/master/INSTALL.md" > INSTALL.md</a > 目录超链接 <a class ="js-navigation-open link-gray-dark" title ="theme" href ="/dracula/powershell/tree/master/theme" > theme</a >
文件和目录链接的区别来源于 Git 的四种 object, tree | blob | commit | tag 分别代表 目录 | 文件 | 提交信息 | 标签,commit别名
# 使用 pyquery 解析outer_html (method=‘html’ )
获得第一个选中元素的 html 表示
1 2 3 >>> d = PyQuery('<div><span class="red">toto</span> rocks</div>' ) >>> print (d('span' ).outer_html()) <span class="red" >toto</span>
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import requestsfrom pyquery import PyQuery as pqbase_url = "https://github.com" ''' 找到Github当前页面下的ps文件,并将目录返回 @param path 相对路径 /dracula/powershell @return list list [psfile0, psfile1, ...] [dir0, dir1, ...] ''' def find_ps (path ): headers = { 'Host' : 'github.com' , 'User-Agent' : 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' , } full_url = base_url + path try : r = requests.get(full_url, headers=headers, timeout=(7 , 10 )) except Exception: return [], [] ps, dirs = [], [] doc = pq(r.text) items = doc('a' ).filter ('.js-navigation-open' ).items() for item in items: if "/tree/" in item.outer_html(): dirs.append(item.text()) elif ".ps1" == item.text(): ps.append(item.text()) else : pass return ps, dirs path = "/dracula/powershell" ps, dirs = find_ps(path) print (ps, dirs)
结果如下:
1 [] ['.github' , 'dist' , 'images' , 'theme' ]
从上面结果可知,程序正确地返回了目录名。但由于一个仓库中有多个子目录,所以更希望程序能够返回 href="/dracula/powershell/tree/master/theme" 中的链接地址。但是 pyquery 功能有限,只针对 html 中的标签做了解析,所以需要需要更强有力的工具 BeautifulSoup
# 使用 BeautifulSoup 解析文档: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
部分文档内容粘贴如下:
一段 html 文本
1 2 3 4 5 6 7 8 9 10 11 12 13 html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """
使用 Beautiful Soup 找到所有 <a> 标签中的链接
1 2 3 4 5 from bs4 import BeautifulSoupsoup = BeautifulSoup(html_doc, 'html.parser' ) for link in soup.find_all('a' ): print (link['href' ])
结果如下:
1 2 3 http://example.com/elsie http://example.com/lacie http://example.com/tillie
搜索 ps 文件函数修改如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import requestsfrom bs4 import BeautifulSoup base_url = "https://github.com" def find_ps (path ): headers = { 'Host' : 'github.com' , 'User-Agent' : 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' , } full_url = base_url + "/" + path try : r = requests.get(full_url, headers=headers, timeout=(7 , 10 )) except Exception: return [], [] ps, dirs = [], [] soup = BeautifulSoup(r.text, 'html.parser' ) for link in soup.find_all("a" , class_="js-navigation-open" ): if "/tree" in link['href' ]: dirs.append(link['href' ]) elif ".ps1" == link['href' ][-4 :]: ps.append(link['href' ]) else : pass for i in range (len (ps)): ps[i] = ps[i].replace("/blob/" , "/" ) return ps, dirs path = "/dracula/powershell" ps, dirs = find_ps(path) print (ps, dirs)
结果如下:
1 [] ['/dracula/powershell/tree/master/.github' , '/dracula/powershell/tree/master/dist' , '/dracula/powershell/tree/master/images' , '/dracula/powershell/tree/master/theme' ]
由于 python 递归过慢,所以采用伪队列的形式对 Github 的仓库目录进行遍历
1 2 3 4 5 6 7 8 9 10 def get_ps_in_repo (path ): ps, dirs = [], ["/" + path] while len (dirs) != 0 : cur_ps, cur_dirs = find_ps(dirs[0 ]) dirs.remove(dirs[0 ]) dirs += cur_dirs ps += cur_ps return ps print (get_ps_in_repo("/dracula/powershell" ))
结果如下:
1 ['/dracula/powershell/master/theme/dracula-prompt-configuration.ps1' ]
只有一个 ps1 文件,与仓库实际情况相同相同
由于我们需要下载 100 个以上的脚本文件,所以需要遍历多个仓库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def traverse_repos (ps_num ): page = 1 ps = [] while True : search_url = 'https://github.com/search?l=PowerShell&q=powershell&type=Repositories&p=' + str (page) repos = get_repos(search_url) for repo in repos: cur_ps = get_ps_in_repo(repo) ps += cur_ps with open ("ps.txt" , "w" ) as f: f.write(str (ps)) if len (ps) > ps_num: return ps page += 1 ps = traverse_repos(100 )
至此,我们就拿到了 100 个.ps1 文件的链接。这个访问的时间非常长,暂时不知道怎么优化,有解决方案的小伙伴可以留言交流一下。
# 多线程下载 Github 文件# 下载单个 github 文件可以通过 https://raw.githubusercontent.com 来下载单个 github 文件
上述文件的链接地址为 https://github.com/MicksITBlogs/PowerShell/raw/master/2013RevitBuildingPremiumUninstaller.ps1
使用 wget 测试能否正常下载
1 wget https://github.com/dracula/powershell/raw/master/README.md
显示跳转到 https://raw.githubusercontent.com/dracula/powershell/master/README.md 进行下载
所以直接将下载前缀改为 https://raw.githubusercontent.com
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import osdef download (url ): raw_base_url = "https://raw.githubusercontent.com" file_url = raw_base_url + url file_name = file_url.split("/" )[-1 ] parent_dir = "./" if os.path.exists(parent_dir + file_name): file_name = randomstr(4 ) + "_" + file_name file_name = parent_dir + file_name try : r = requests.get(file_url) with open (file_name, 'wb' ) as f: f.write(r.content) except requests.ConnectionError: pass download("/dracula/powershell/master/screenshot.png" )
# 多线程下载不复杂,直接上代码
1 2 3 4 5 6 7 8 from multiprocessing import Pool def multi_process (ps_files ): process_pool = Pool(4 ) for i in ps_files: process_pool.apply_async(download, args=(i,)) process_pool.close() process_pool.join()
《或者所谓春天》(节选)
余光中
所谓童年
所谓抗战
所谓高二
所谓大三
所谓蜜月,并非不月蚀
所谓贫穷,并非不美丽
所谓妻,曾是新娘
所谓新娘,曾是女友
所谓女友,曾非常害羞
所谓不成名以及成名
所谓朽以及不朽
或者所谓春天